MoDi: Unconditional Motion Synthesis from Diverse Data
Abstract
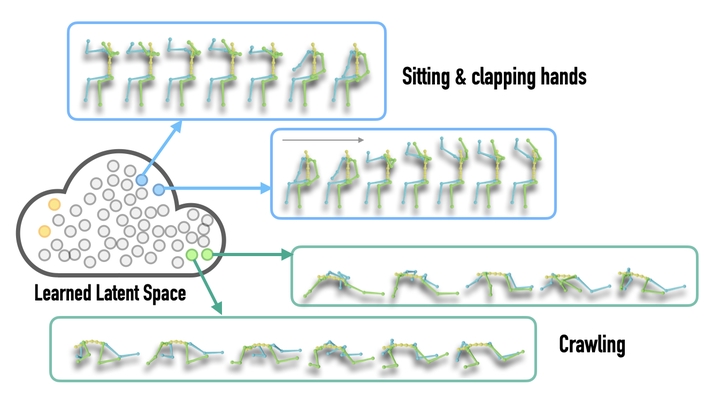
The emergence of neural networks revolutionized motion synthesis, yet synthesizing diverse motions remains challenging. We present MoDi, an unsupervised generative model trained on a diverse, unstructured, unlabeled dataset, capable of synthesizing high-quality, diverse motions. Despite dataset’s lack of structure, MoDi yields a structured latent space for semantic clustering, enabling applications like semantic editing and crowd simulation. We also introduce an encoder that inverts real motions into MoDi’s motion manifold, addressing ill-posed challenges like completion from prefix and spatial editing, achieving state-of-the-art results surpassing recent techniques.
Type
Publication
CVPR 2023